Dec 3, 2025·4 min read
The Case for Task-Aware Reasoning Budget Allocation
Research from DeepSeek, Berkeley, and Google DeepMind shows that reasoning budgets must be allocated based on task structure, not maximized by default. Here's the evidence and a routing architecture.
The Problem
Most LLM deployments treat reasoning effort as a global setting. High reasoning for "important" tasks, low for simple ones. This is wrong.
Research from DeepSeek, Berkeley, and Google DeepMind converges on a different model: reasoning budget allocation must be task-aware. The optimal configuration depends on task structure, not task importance.
The Research
DeepSeek R1 (January 2025) demonstrated that mid-sized models (32B-70B parameters) could match frontier closed-source models on math and code benchmarks purely through scaled test-time compute. The key finding: inference compute substitutes for parameter count.
But R1 also demonstrated the inverse. When you allocate both massive parameters and extended reasoning to a constrained problem, you get redundancy, not better results.
"Scaling LLM Test-Time Compute Optimally" from Berkeley and Google DeepMind formalized this relationship. The paper establishes that optimal compute allocation depends on task structure. For some problems, more thinking helps. For others, it actively hurts. Their compute-optimal strategy improved efficiency by 4x compared to naive best-of-N approaches.
"Stop Overthinking: A Survey on Efficient Reasoning" documents the failure mode. When reasoning budget exceeds task complexity, models generate redundant verification steps, explore hypothetical edge cases that don't apply, and sometimes reason themselves into worse solutions. The authors call it the "overthinking phenomenon": when asked "Which is larger, 0.9 or 0.11?", DeepSeek-R1 took 42 seconds to answer.
The Mechanism
When you allocate a high reasoning budget to a large model for a medium-complexity task, it doesn't just solve the problem. It begins to critique the problem.
The model questions input validity. It simulates failure modes that can't occur in your environment. It rewrites your requirements in its internal reasoning, then solves the rewritten version instead of the original.
More steps. Same output. Worse economics.
Contrast this with a smaller model given high reasoning effort. It lacks the world-model depth to overcomplicate things. Its reasoning budget gets spent on what you actually asked for: verifying constraints, checking edge cases, validating syntax.
The principle: Model capacity and reasoning budget are independent variables. Task-aware allocation means tuning both based on task structure.
Empirical Validation
I've validated this pattern on a project I'm working on. While building a multi-tool ETL architecture for querying, preparing and transforming data to be displayed, I ran controlled experiments across model configurations:
| Configuration | Reasoning Effort | Outcome |
|---|---|---|
| gpt-5-mini | High | Best performer. Step-by-step schema validation. Zero syntax errors. |
| gpt-5.1 | None | Failed. Hallucinated column names. Missed edge cases. |
| Claude Sonnet 4.5 | Low | Runner-up. Fast, efficient, minimal overhead. |
| Claude Opus 4.5 | High | Inefficient. Completed eventually, but took 3x the steps. |
The Opus result matches the research predictions. It didn't fail; it overthought. It questioned schema validity, simulated race conditions that couldn't happen locally, and adjusted its own queries multiple times before execution.
Small model with high reasoning outperformed large model with high reasoning on this structured task.
A Task-Aware Routing Architecture
Static reasoning_effort configuration is the root problem. Allocation must be dynamic and task-aware.
Here's a router that classifies incoming prompts and allocates reasoning budget accordingly:
import { generateObject } from "ai";
import { google } from "@ai-sdk/google";
import { z } from "zod";
type ReasoningTier =
| "SYSTEM_1" // Fast, no deliberation
| "SYSTEM_2_LITE" // Small model, high reasoning
| "SYSTEM_2_DEEP" // Large model, moderate reasoning
| "EXTENDED_ARCHITECT"; // Large model, extended thinking
const ClassificationSchema = z.object({
complexityScore: z.number().min(1).max(10),
taskType: z.enum(["logic", "creative", "retrieval", "coding"]),
requiresWorldKnowledge: z.boolean(),
});
async function classifyPrompt(userPrompt: string) {
const { object } = await generateObject({
model: google("gemini-2.5-flash"),
schema: ClassificationSchema,
prompt: `Analyze this request for complexity and type: "${userPrompt}"`,
});
return object;
}
export async function allocateReasoningBudget(
userPrompt: string
): Promise<ReasoningTier> {
const { complexityScore, taskType, requiresWorldKnowledge } =
await classifyPrompt(userPrompt);
// Deterministic tasks: JSON formatting, typo fixes
// Risk: Any reasoning budget causes over-analysis
if (complexityScore <= 3) {
return "SYSTEM_1";
}
// Structured logic: SQL, regex, transformations
// Optimal: Small model + high reasoning
if (taskType === "coding" || taskType === "logic") {
return "SYSTEM_2_LITE";
}
// High ambiguity + high complexity: strategy, architecture
// Optimal: Large model + extended thinking
if (requiresWorldKnowledge && complexityScore >= 8) {
return "EXTENDED_ARCHITECT";
}
return "SYSTEM_2_DEEP";
}
The classifier runs on a cheap, fast model. It adds ~100ms latency but can save 10x compute on misallocated requests.
Allocation Heuristics
The routing logic reduces to task structure analysis:
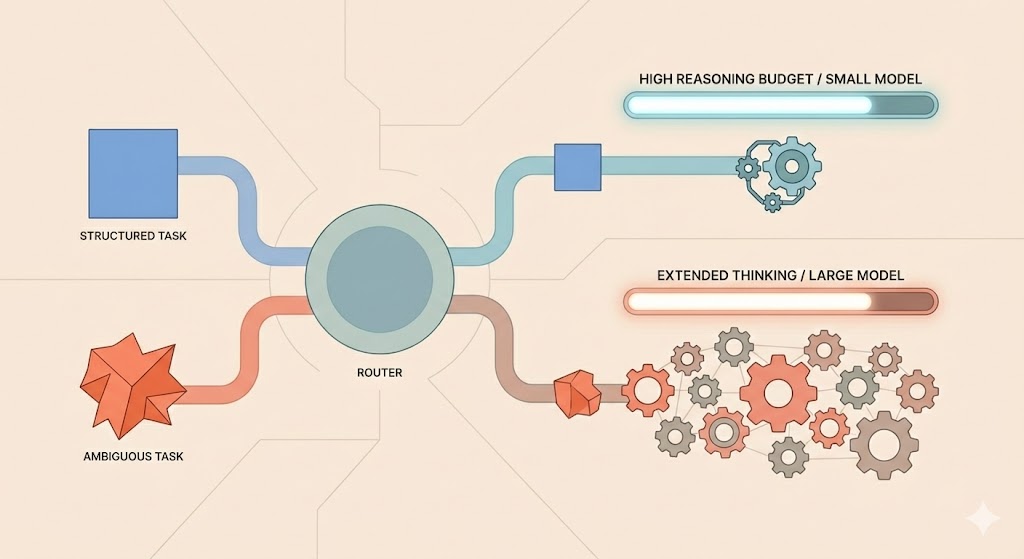
Structured tasks (SQL, regex, JSON, validation): Allocate high reasoning to a small model. Constrained reasoning on constrained problems prevents overthinking.
Ambiguous tasks (creative writing, strategy, open-ended design): Allocate extended thinking to a large model. The task requires the world-model depth that large models provide.
Mixed tasks: Default to SYSTEM_2_LITE. Escalate on failure.
Production Tradeoffs
Task-aware routing adds a classification step. The tradeoffs:
- Lower costs. Most requests route to cheaper configurations.
- Better latency. Small models with appropriate reasoning are faster than large models overthinking.
- Higher success rates. Matching allocation to task structure reduces both under- and over-provisioning.
The classifier itself is a potential failure point. In practice, simple heuristics (keyword matching, prompt length, presence of code blocks) catch 80% of cases without any LLM call.
References
-
Scaling LLM Test-Time Compute Optimally Can be More Effective than Scaling Parameters (Snell et al., ICLR 2025). Establishes that optimal compute allocation depends on task structure.
-
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models (TMLR, 2025). Documents the overthinking phenomenon and categorizes efficient reasoning approaches.
-
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (DeepSeek-AI, January 2025). Demonstrates that reasoning capacity and model size are independent variables.
Summary
Reasoning budget allocation is not a global optimization problem. It's a per-task allocation problem.
The research is clear: the relationship between model capacity, reasoning budget, and task complexity is nonlinear. Maximizing reasoning effort on structured tasks causes overthinking. Minimizing it on ambiguous tasks causes underthinking.
Task-aware routing solves this. Classify the prompt, allocate the appropriate budget, escalate on failure.
Model intelligence and reasoning depth are separate resources. Allocate them based on task structure.